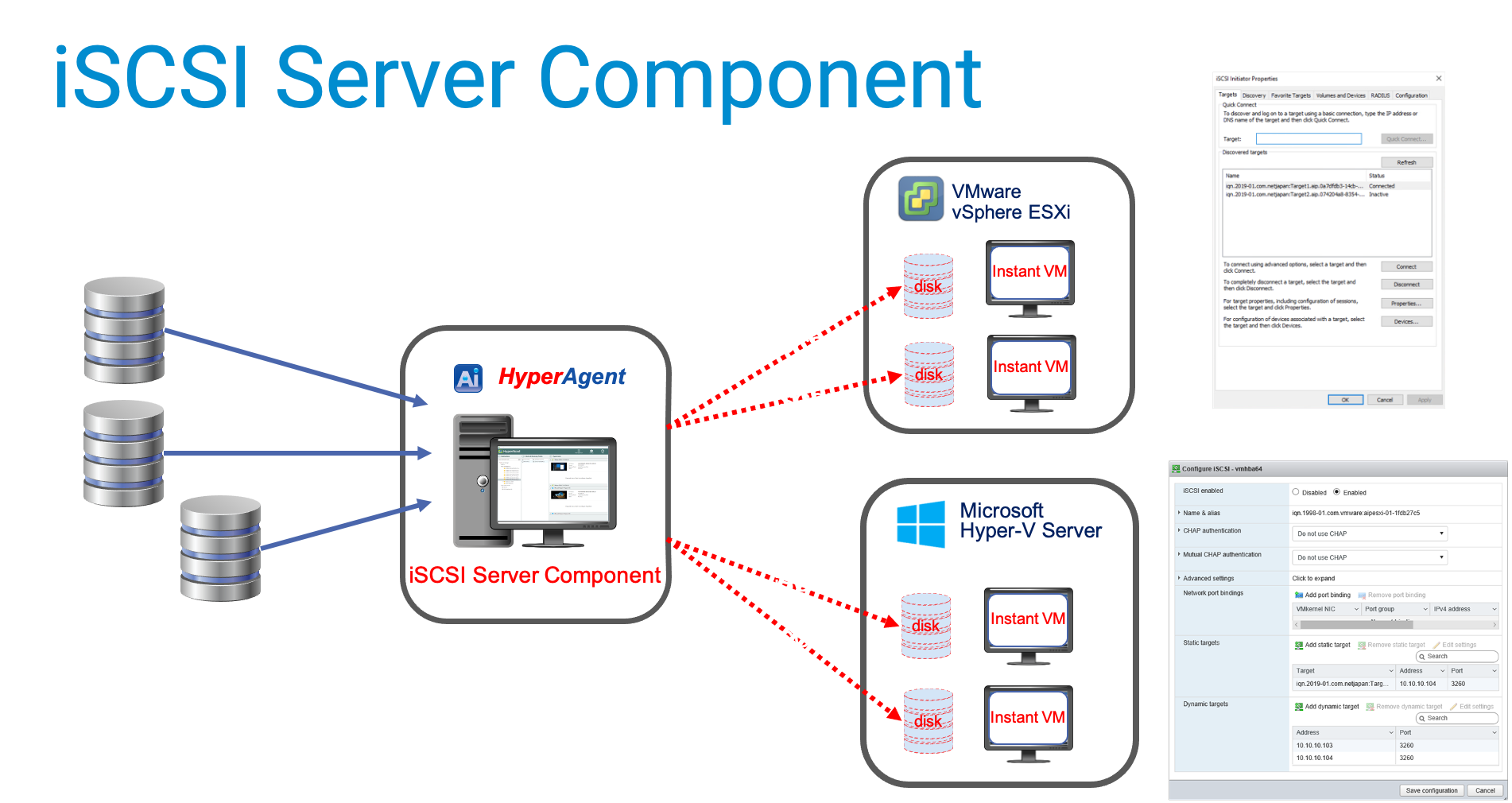
Backup scheduling best practises to ensure availability

Imagine a scale where the two endpoints represent two extreme data protection policies.
The endpoint on the left-hand side of the scale is marked, “good backup of the system when it was configured and released into Production” (i.e. “day-zero backup”).
The endpoint on the right-hand side of the scale is marked, “real-time mirroring/replication”.
These two marks represent two extreme cases in backup scheduling:
“real-time mirror/replica” actually assumes there is no need for a backup schedule; the backup happens in real-time, all the time.,
In practice, most businesses will not choose real-time replication of their data; and will instead put in place a backup schedule to protect data created after the initial “day-zero” backup.
Several factors must be considered before implementing the correct backup policies to meet the required (RPO) Recovery Point Objectives.
· How often we need to backup an entire system, disks/volumes, data and databases, AD/configuration, network files, other critical systems and data, user’s data?
· What each backup software is capable of, what type of data the software can see and can backup separately from the rest?
Some of the vendors offer a wide variety of options such as backup up entire systems, separate disks/volumes, files/folders, databases, and mail applications.
Other vendors focus on machine/disks/volumes level and include the ability to recover the rest of the above-listed items from this level backups.
Regarding the frequency of backups, a surface conclusion is the more frequently we backup the data, the more granularity we have in the sense of possible recovery points.
– Frequency of backups – What impact on production resources?
– Any backup in progress must not cause degradation or failure to any production activity/process.
Most of the backup vendors provide means to limit resource consumption (CPU, network bandwidth) by backup processes.
– Nevertheless, lowering resource consumption causes a longer time for the backup task to finish. This may contradict with other critical requirements.
Moreover, some aspects of backup tasks might not be easy to control/restrict in sense of CPU/RAM/disk I/O consumption. For example, VSS snapshots which are widely used by all vendors on Windows systems and triggered at the beginning of each backup task.
– Impact on Storage Resources – The more frequently the backup task occurs, the more often new backup data hits the destination storage, more data is accumulated, consuming more storage. The storage maximum capacity can be reached sooner.
To address this side-effect most of the backup vendors offer “Retention Policy” – a software means to get rid of the older backups so the storage will longer before it is 100% consumed.
In addition to retention policies, some of the backup vendors provide software components/tools to replicate backups offsite; where the Retention Policy restrictions can be more modest and data can be accommodated in larger sizes.
The backup scheduling topic goes hand-to-hand with other topics like “Full vs Incremental vs Differential: Comparing Backup Types”, “3-2-1 Backup Strategy”. Please check out our other blog articles.
In short:
A Full backup set represents a full set of data which had been intended to be protected.
A Differential backup contains only changes compared with Full backup.
An Incremental backup contains only changes compared with the last previously created backup (which might be Full, Differential, or Incremental).
Obviously, a Full backup consumes the most storage space of all three backup types.
A Differential backup can be small in size if created soon after Full but may also be of significant size if taken a few weeks/months after the last full backup, since it’s content will always differ from the
An Incremental backup is the ‘smallest’ of the three backup types. The only downside – it always depends on the previously created backup. So, if you build a long chain of Increments – you are potentially reducing the reliability of the backups.
The solution to this “long-incremental” chain is the real need to occasionally create a new full backup.
Now with this “occasionally” remark, we enter the real world where we face limitations of storage, network bandwidth and so on. We may realize that “full backup occasionally” requirement is easy to digest but might not be so easy to follow.
The concept of “Incremental Forever” comes to the rescue in such cases. This concept had been mastered especially around the cases with scarce/limited network resources, where the full backup transfer would take days and weeks to complete.
“Incremental Forever” offers to create a full backup only once and defines Incremental backups for the rest of the time.
To avoid the “long-incremental chain” reliability issue, backup vendors offer smart methods to consolidate the multiple Increments into a single file so the number of items in the chain can be reduced and dynamically controlled.
Scheduled Boot Checks to check the health of backup sets is offered by vendors along with components/tools to run ad-hoc or scheduled Boot Checks – attempts to boot a temporary VM directly from the latest item of a backup chain.
If such attempt succeeds – the attempt is marked successful and indicates the good health of the backup chain. A failure of such a test is a clear indication to a backup operator: it’s time to create a new Full backup.
Backup scheduling best practises to ensure availability Read More »